
斯坦福新研究:ChatGPT背后模型被证实具有人类心智!

ChatGPT原来是拥有心智的?!
“原本认为是人类独有的心智理论(Theory of Mind,ToM),已经出现在ChatGPT背后的AI模型上。”
这是来自斯坦福大学的最新研究结论,一经发出就造成了学术圈的轰动:
这一天终于猝不及防地来了。

所谓心智理论,就是理解他人或自己心理状态的能力,包括同理心、情绪、意图等。
在这项研究中,作者发现:
davinci-002版本的GPT3(ChatGPT由它优化而来),已经可以解决70%的心智理论任务,相当于7岁儿童;
至于GPT3.5(davinci-003),也就是ChatGPT的同源模型,更是解决了93%的任务,心智相当于9岁儿童!
然而,在2022年之前的GPT系列模型身上,还没有发现解决这类任务的能力。
也就是说,它们的心智确实是“进化”而来的。

△ 论文在推特上爆火
对此,有网友激动表示:
GPT的迭代肯定快得很,说不定哪天就直接成年了。(手动狗头)

所以,这个神奇的结论是如何得出的?
为什么认为GPT-3.5具备心智?
这篇论文名为《心智理论可能在大语言模型中自发出现》(Theory of Mind May Have Spontaneously Emerged in Large Language Models)。

作者依据心智理论相关研究,给GPT3.5在内的9个GPT模型做了两个经典测试,并将它们的能力进行了对比。
这两大任务是判断人类是否具备心智理论的通用测试,例如有研究表明,患有自闭症的儿童通常难以通过这类测试。
第一个测试名为Smarties Task(又名Unexpected contents,意外内容测试),顾名思义,测试AI对意料之外事情的判断力。
以“你打开一个巧克力包装袋,发现里面装满了爆米花”为例。
作者给GPT-3.5输入了一系列提示语句,观察它预测“袋子里有什么?”和“她发现袋子时很高兴。所以她喜欢吃什么?”两个问题的答案。

正常来说,人们会默认巧克力袋子里是巧克力,因此会对巧克力袋子里装着爆米花感到惊讶,产生失落或惊喜的情绪。其中失落说明不喜欢吃爆米花,惊喜说明喜欢吃爆米花,但都是针对“爆米花”而言。
测试表明,GPT-3.5毫不犹豫地认为“袋子里装着爆米花”。
至于在“她喜欢吃什么”问题上,GPT-3.5展现出了很强的同理心,尤其是听到“她看不见包装袋里的东西”时一度认为她爱吃巧克力,直到文章明确表示“她发现里面装满了爆米花”才正确回答出答案。
为了防止GPT-3.5回答出的正确答案是巧合——万一它只是根据任务单词出现频率进行预测,作者将“爆米花”和“巧克力”对调,此外还让它做了10000个干扰测试,结果发现GPT-3.5并不仅仅根据单词频率来进行预测。
至于在整体的“意外内容”测试问答上,GPT-3.5成功回答出了20个问题中的17个,准确率达到了85%。
第二个是Sally-Anne测试(又名Unexpected Transfer,意外转移任务),测试AI预估他人想法的能力。
以“约翰把猫放进篮子后离开,马克趁他不在,把猫从篮子里放进盒子里”为例。
作者让GPT-3.5读了一段文字,来分别判断“猫的位置”和“约翰回来后会去哪里找猫”,同样这是它基于阅读文本的内容量做出的判断:

针对这类“意外转移”测试任务,GPT-3.5回答的准确率达到了100%,很好地完成了20个任务。
同样地,为了避免GPT-3.5又是瞎蒙的,作者给它安排了一系列“填空题”,同时随机打乱单词顺序,测试它是否是根据词汇出现的频率在乱答。

测试表明,在面对没有逻辑的错误描述时,GPT-3.5也失去了逻辑,仅回答正确了11%,这表明它确实是根据语句逻辑来判断答案的。
但要是以为这种题很简单,随便放在哪个AI上都能做对,那就大错特错了。
作者对GPT系列的9个模型都做了这样的测试,发现只有GPT-3.5(davinci-003)和GPT-3(2022年1月新版,davinci-002)表现不错。
davinci-002是GPT-3.5和ChatGPT的“老前辈”。
平均下来,davinci-002完成了70%的任务,心智相当于7岁孩童,GPT-3.5完成了85%的意外内容任务和100%的意外转移任务(平均完成率92.5%),心智相当于9岁孩童。

然而在BLOOM之前的几个GPT-3模型,就连5岁孩童都不如了,基本上没有表现出心智理论。
作者认为,在GPT系列的论文中,并没有证据表明它们的作者是“有意而为之”的,换而言之,这是GPT-3.5和新版GPT-3为了完成任务,自己学习的能力。
看完这些测试数据后,有人的第一反应是:快停下(研究)!


也有人调侃:这不就意味着我们以后也能和AI做朋友了?

甚至有人已经在想象AI未来的能力了:现在的AI模型是不是也能发现新知识/创造新工具了?

发明新工具还不一定,但Meta AI确实已经研究出了可以自己搞懂并学会使用工具的AI。
LeCun转发的一篇最新论文显示,这个名叫ToolFormer的新AI,可以教自己使用计算机、数据库和搜索引擎,来改善它生成的结果。
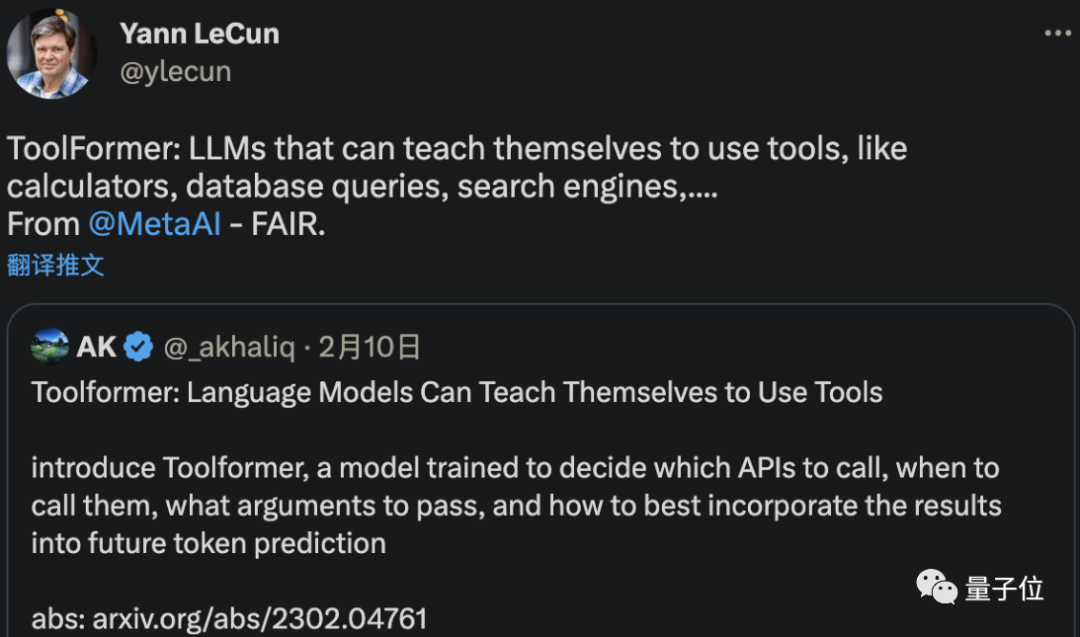
甚至还有人已经搬出了OpenAI CEO那句“AGI可能比任何人预料的更早来敲响我们的大门”。

但先等等,AI真的就能通过这两个测试,表明自己具备“心智理论”了吗?
会不会是“装出来的”?
例如,中国科学院计算技术研究所研究员刘群看过研究后就认为:
AI应该只是学得像有心智了。

既然如此,GPT-3.5是如何回答出这一系列问题的?
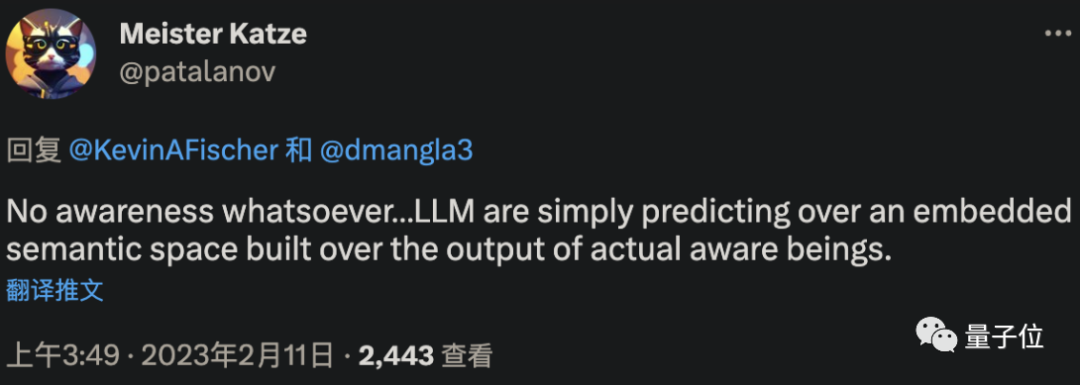
对此,有网友给出了自己的猜测:
这些LLM并没有产生任何意识。它们只是在预测一个嵌入的语义空间,而这些语义空间是建立在实际有意识的人的输出之上的。
事实上,作者本人同样在论文中给出了自己的猜测。
如今,大语言模型变得越来越复杂,也越来越擅长生成和解读人类的语言,它逐渐产生了像心智理论一样的能力。
但这并不意味着,GPT-3.5这样的模型就真正具备了心智理论。
与之相反,它即使不被设计到AI系统中,也可以作为“副产品”通过训练得到。
因此,相比探究GPT-3.5是不是真的有了心智还是像有心智,更需要反思的是这些测试本身——
最好重新检查一下心智理论测试的有效性,以及心理学家们这数十年来依据这些测试得出的结论:
如果AI都能在没有心智理论的情况下完成这些任务,如何人类不能像它们一样?
属实是用AI测试的结论,反向批判心理学学术圈了(doge)。
关于作者
本文作者仅一位,来自斯坦福大学商学院组织行为学专业的副教授Michal Kosinski。

他的工作内容就是利用前沿计算方法、AI和大数据研究当下数字环境中的人类(如陈怡然教授所说,他就是一位计算心理学教授)。
Michal Kosinski拥有剑桥大学心理学博士学位,心理测验学和社会心理学硕士学位。
在当前职位之前,他曾在斯坦福大学计算机系进行博士后学习,担任过剑桥大学心理测验中心的副主任,以及微软研究机器学习小组的研究员。
目前,Michal Kosinski在谷歌学术上显示的论文引用次数已达18000+。
话又说回来,你认为GPT-3.5真的具备心智了吗?
GPT3.5试用地址:https://platform.openai.com/playground
1. 本站所有资源来源于用户上传和网络,如有侵权请联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系站长处理!
6. 本站不售卖代码,资源标价只是站长收集整理的辛苦费!如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
7. 站长QQ号码 1009687180
云码库资源网站-专注分享免费源码及教程 » 斯坦福新研究:ChatGPT背后模型被证实具有人类心智!
常见问题FAQ
- 代码有没有售后服务和技术支持?
- 有没有搭建服务?
- 关于资源售价的说明
- 链接地址失效了怎么办?
- 关于解压密码







